
Processing a single $50 return costs retailers an average of $33, or 66% of the item's original price, according to industry data on return processing costs. That number changes how you think about returns. This isn't a back-office nuisance. It's a margin leak that can overwhelm growth, especially in categories where customers order multiple sizes, colors, or variants with the intention of sending some back.
The companies that handle returns well don't just cut labor. They use returns management automation to recover revenue, protect loyalty, and put sellable inventory back to work faster. That's the real shift. Returns stop being a pure cost center and start becoming an operational system you can tune for retention and profit.
Why Returns Are an Existential E-commerce Threat
Organizations often underestimate returns because they look at refund value and miss processing cost. The refund is obvious. The operational drag isn't. Warehouse handling, customer support, label creation, routing decisions, inventory reconciliation, and refund exceptions all pile onto the same event.
That's why the economics get ugly fast. A return isn't just a reversed sale. It's a new workflow with its own labor, systems, and failure points. And when that workflow is still managed through inboxes, spreadsheets, and disconnected apps, every return consumes more time than it should.
The margin damage compounds quickly
Online retail faces a very different return profile than stores. Return rates reached approximately 20.8% for online purchases, versus 16.6% across total U.S. retail sales, and climbed as high as 25% to 40% for items purchased online, compared with 8% for brick-and-mortar purchases in the verified industry data provided above. That gap is the heart of the e-commerce problem. Digital shopping creates more uncertainty before purchase, so reverse logistics becomes part of the normal operating model.
Manual handling doesn't scale under those conditions. One support agent answers status questions. Another checks policy exceptions. A warehouse lead decides whether an item goes back into stock or into a secondary path. Finance waits for clean data before reconciling refunds. None of that is unusual. That's exactly why it becomes dangerous.
Practical rule: If returns volume rises and your process still depends on people forwarding emails and updating spreadsheets, you don't have a returns process. You have a labor bottleneck.
There's also a second-order effect many operators miss. Poor returns handling doesn't stay inside the returns department. It drives ticket volume, clogs warehouse receiving, delays inventory accuracy, and increases payment disputes when customers don't understand refund timing. Teams already dealing with payment friction should also look at resources on managing high chargeback rates, because unclear post-purchase communication often shows up in both disputes and returns operations.
Why this becomes a growth ceiling
A business can survive a clunky process at low volume. It can't scale one. The moment order volume increases, returns create queueing everywhere. Customers wait longer. Agents answer the same questions repeatedly. Warehouse teams process units in batches instead of flows. Refund timing stretches, and trust drops.
That's why returns management automation isn't a nice-to-have in 2026. It's the point where operational maturity starts. Without it, growth can make the business less profitable.
What Is Returns Management Automation
Returns management automation is the use of connected software, rules, and integrations to handle the return lifecycle without relying on manual coordination at every step. In practice, that means the system gathers order data, applies policy, generates labels or exchange options, routes items correctly, updates internal systems, and keeps the customer informed.
The simplest way to understand it is to compare before and after.
Before automation, a customer asks for a return, support checks the order, someone reviews policy, a label gets created, warehouse staff wait for paperwork, finance waits for confirmation, and the customer keeps asking for updates.
After automation, the return request triggers a controlled workflow. The customer sees eligible options immediately. The business decides what should happen through rules. Internal systems update as events occur instead of after someone catches up.

The business problem it solves
The scale alone justifies taking this seriously. The global volume of returned merchandise recently exceeded $761 billion, accounting for 16.6% of total U.S. retail sales, up from 10.6% in 2020, according to verified industry data on returned merchandise volume. At that level, returns can't be treated as an exception path. They're a permanent operating function.
What matters is that automation changes the economics of that function.
It reduces avoidable handling. It standardizes decisions. It shortens the time between customer action and business response. And it gives operators something manual systems rarely provide: a clean, measurable process.
What good automation actually looks like
A strong automated returns setup usually includes these outcomes:
Customer self-service: Shoppers can start a return or exchange without waiting for support.
Policy enforcement: The system applies category, value, timing, and condition rules consistently.
Faster resolution: Refunds, exchanges, and routing decisions move without internal chasing.
Better visibility: Support, warehouse, and finance all work from the same event trail.
Inventory recovery: Resellable items get back into available stock faster.
That last point is where many guides stop short. Cost reduction matters, but inventory recovery and exchange capture are what turn returns into a strategic lever.
Returns management automation works best when it treats the return as a commercial event, not just a warehouse event.
For a simple consumer-facing example of how return experience affects trust, a brand-specific walkthrough like the Albion Fit returns guide is useful because it shows what customers look for: clarity, timing, and low-friction instructions.
The KPIs that matter
If you're evaluating returns management automation, track a small set of metrics that connect operations to margin:
KPI | What it tells you |
|---|---|
Cost per return | The true operational burden of each return |
Return rate by SKU | Which products create repeat reverse-logistics pain |
Exchange rate | How often a return becomes retained revenue |
Time to resolution | How long customers wait for a completed outcome |
Inventory reintegration speed | How quickly sellable units return to stock |
Support contact rate for returns | Whether the process is clear enough to reduce inbound tickets |
When those metrics improve together, the business usually sees three things happen. Margins stabilize, customer frustration falls, and returns become easier to plan rather than react to.
The Core Components of an Automated System
A solid returns stack isn't one feature. It's a chain of decisions and actions that work together. If one link stays manual, the whole process slows down.
The most effective systems are built around a simple idea: every return should move through a controlled path from request to final disposition, with as little human intervention as possible unless the case needs judgment.

The customer-facing layer
The first component, the returns portal, allows customers to identify their order, select a reason, choose an outcome, and receive instructions. Good portals reduce confusion. Bad ones push customers into support queues.
What matters here isn't flashy design. It's decision quality. The portal should offer only the paths that make sense for that order, product, and policy. That alone removes a huge amount of manual triage.
The second component is automated authorization. If an order is eligible, the system should approve it immediately and trigger the next action. If it isn't, the customer should see a clear explanation or an alternate path, not a generic denial that creates another ticket.
The rules engine is where profit is recovered
The most important part of returns management automation is the rules engine, through which the business decides what should happen based on item value, product category, reason code, customer history, and downstream economics.
For example, a low-value item may not justify shipping back. A high-demand item might be routed to an exchange-first flow. A damaged item may need inspection before any financial action occurs.
This is also where revenue recovery happens. Verified data shows that automated platforms can re-converge 30% of returned goods into new sales within the same operational cycle, according to industry data on exchange-driven revenue recovery. That's the difference between treating a return as a loss and treating it as a retention opportunity.
A practical setup often includes rules like these:
Exchange-first offers: Present replacement sizes, colors, or variants before defaulting to refund.
Disposition routing: Send items toward resale, refurbishment, recycling, or exception review automatically.
Returnless refund decisions: Reserve shipping and handling for items that justify it.
Reason-code actions: Route defect-related returns differently from fit or preference returns.
The operational control layer
Once the return is in motion, the system needs to manage execution.
That includes:
Carrier integrations for label creation and status tracking
Warehouse receiving logic so staff know what to inspect and where to route it
Refund or exchange triggers that fire at the right event, not whenever someone remembers
Analytics and reporting so operators can identify recurring product, policy, or fraud problems
Many implementations break because teams automate request intake but leave receiving, finance handoff, and reporting manual. That creates a faster front end with the same back-end bottlenecks.
If your portal is automated but warehouse disposition still depends on side messages and ad hoc decisions, you've only digitized the queue.
Fraud and exception handling belong here too. Some operators connect return review logic with broader risk systems. If you're comparing approaches, this guide to automated risk assessment tools is useful for thinking about where automated scoring helps and where manual review still matters.
The end state is straightforward. Customers get clarity. Ops gets consistency. Finance gets clean event data. The warehouse gets instructions instead of ambiguity.
The Technology Stack and Key Integrations
Returns automation only works when it's wired into the rest of the business. A standalone portal can collect requests, but it can't produce reliable outcomes on its own. The primary value comes from integration.
The core architecture is a central returns platform connected to the systems that already run commerce, fulfillment, support, and finance. Without those connections, teams end up rekeying data, reconciling exceptions manually, and arguing about which system reflects the truth.

The systems that must connect
At minimum, an effective setup ties together these systems:
System | Why it matters |
|---|---|
E-commerce platform or OMS | Supplies order data, line items, customer details, and payment context |
WMS | Controls receiving, inspection, putaway, and inventory status |
ERP or finance system | Handles refund reconciliation, accounting treatment, and reporting |
Helpdesk or CRM | Gives support agents full visibility into return status and history |
Carrier network | Supports labels, scans, shipment status, and delivery confirmation |
When these systems share data in real time, the return becomes an event stream rather than a chain of handoffs. The customer starts a request. The policy engine evaluates it. The carrier receives instructions. The warehouse receives expected returns data. Finance sees the appropriate trigger. Support sees the same timeline.
That's what people mean by a single source of truth. Not a dashboard. A shared operational record.
Why the API layer matters so much
The technical value of returns automation depends on API integration and dynamic policy logic. Verified data notes that advanced systems can apply granular rules such as returnless refund for items under $15, reducing unnecessary shipping and handling through dynamic policy engine design.
That matters because not every return should follow the same path. The platform needs to decide quickly and consistently based on business logic, not staff memory.
A few integration decisions separate strong implementations from weak ones:
Event-driven updates: Inventory and refund states should update from actual milestones, not batch spreadsheets.
Shared reason codes: Support, warehouse, and merchandising should analyze the same return categories.
Exception routing: High-risk, high-value, or incomplete cases should route to review queues automatically.
Facility-specific logic: Different warehouses may need different receiving and disposition rules.
For operators redesigning physical workflows alongside software, resources on smart facility design from Material Handling USA can help connect warehouse layout decisions with returns throughput.
Integration mistakes to avoid
Two patterns cause most integration failures.
First, teams connect the portal to the storefront but not to warehouse and finance systems. That creates a polished customer experience with weak internal execution.
Second, they automate fixed workflows instead of designing flexible logic. Returns aren't uniform. Policies vary by item, market, condition, and customer segment. Your stack should support that complexity cleanly.
There's a useful parallel in other forms of operational automation. This overview of automation workflow design is nominally about a different use case, but the lesson carries over: fragmented tools create local wins, while connected systems create durable process improvement.
Your Phased Implementation Roadmap
Most returns automation projects fail when teams try to replace everything at once. The better approach is phased. You start with the highest-friction points, prove operational control, then add deeper logic and integrations once the basics are stable.
That keeps risk down and makes adoption easier across support, warehouse, finance, and merchandising.
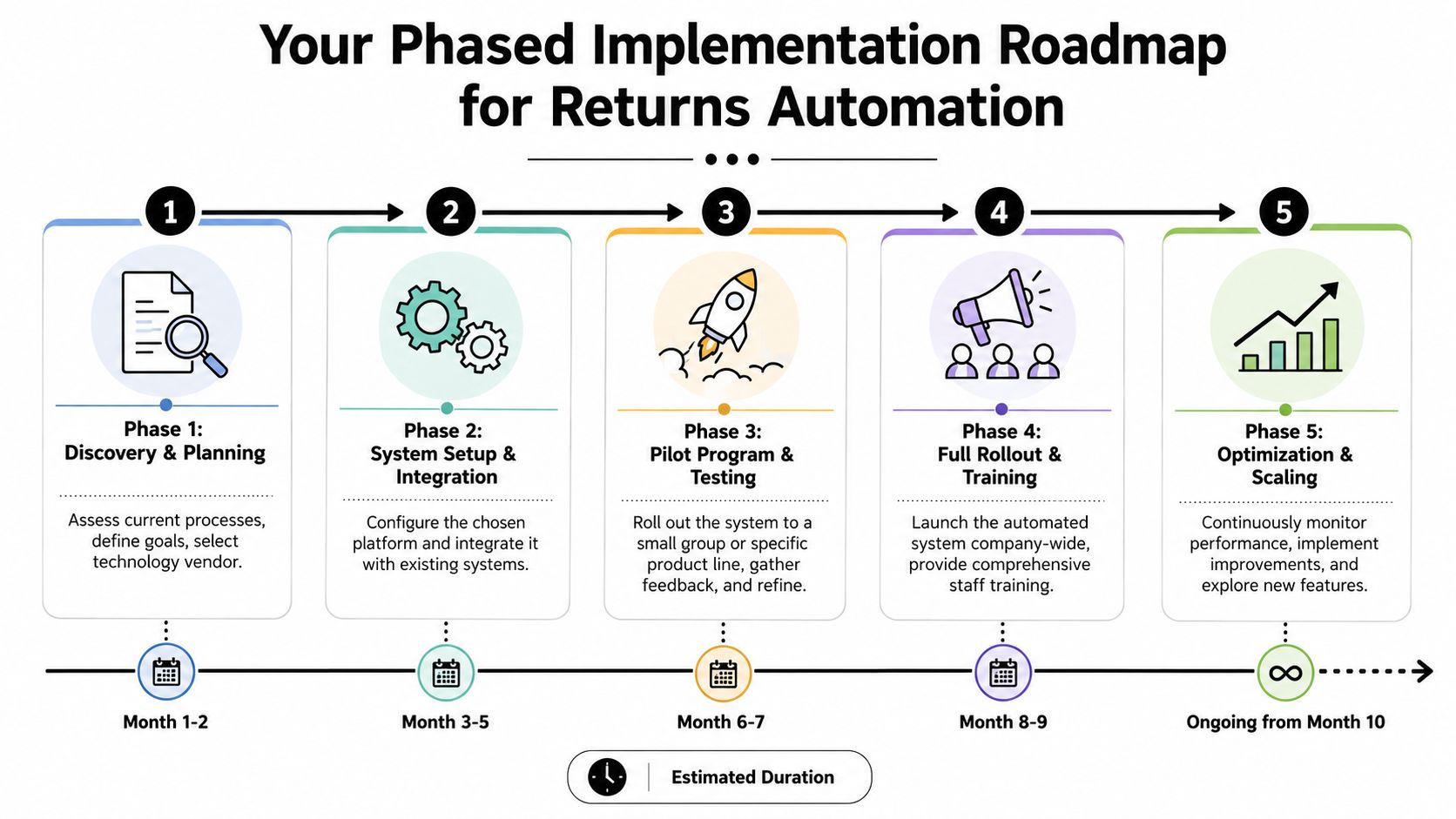
Phase one and phase two
Start with discovery and process mapping. Don't buy software before you understand where delays and errors occur. Map the current flow from customer request through refund reconciliation. Document every approval, manual touch, spreadsheet, exception path, and customer contact point.
Then move into quick-win setup. This usually means a branded self-service portal, automated eligibility checks, and label generation. Those changes remove repetitive support work fast and create a cleaner intake process for the operation.
Focus on a small set of design questions:
Which return reasons should trigger exchanges first
Which products need inspection before refund
Which items should follow a returnless path
Which teams need visibility at each event
If you answer those early, configuration gets simpler.
Phase three and phase four
The next stage is system integration and controlled rollout. Connect the returns platform to order data, helpdesk tools, warehouse workflows, and finance systems. Don't roll it out company-wide on day one if your catalog or policy logic is messy. Pick one category, one market, or one fulfillment node and test there first.
Use the pilot to validate practical details:
Question | What to check |
|---|---|
Does warehouse receiving match portal instructions | Make sure staff see the same logic customers were given |
Do refund triggers fire at the right moment | Avoid premature refunds and delayed customer resolution |
Are exchange flows intuitive | Confirm customers can choose replacement options easily |
Are exception queues manageable | Ensure edge cases reach the right people quickly |
Once the pilot is stable, move to full rollout and training. Many teams, however, underinvest in this phase. A returns system changes daily work. Support agents need to trust the status data. Warehouse teams need disposition rules they can follow. Finance needs confidence in transaction timing and auditability.
Train teams on decision logic, not just on screens. If people don't understand why the system made a choice, they'll bypass it the first time pressure rises.
Phase five
The last phase is optimization. It is then that returns management automation starts paying beyond labor savings.
Look for patterns in reason codes, disposition outcomes, exchange acceptance, and reintegration delays. Feed that back into merchandising, product quality, policy design, and customer communication. A SKU with recurring fit issues may need sizing content changes. A product with repeated defect returns may need supplier review. A category with strong exchange behavior may justify a more aggressive exchange-first flow.
This is also the point where some teams evaluate adjacent automation tools in other domains. For example, platforms like Yield Seeker use automated decisioning and continuous monitoring in a different operational context, allocating stablecoin capital across DeFi protocols based on user preferences. It's not a returns tool, but it's a useful reminder that automation works best when the system can react to changing conditions instead of waiting for manual intervention.
A phased roadmap keeps the project practical. It also makes performance easier to measure, because each step should remove a specific bottleneck rather than introducing a giant bundle of changes all at once.
Common Pitfalls and How to Avoid Them
The biggest mistake in returns automation is thinking more automation is always better. It isn't. Bad automation scales bad decisions.
The strongest programs know where to automate hard and where to keep human judgment in the loop.
Over-automation in fraud detection
Fraud screening is the clearest example. Verified data shows that 30% of automated fraud flags are false positives, and a hybrid human-in-the-loop model can reduce those false positives by 40% while maintaining effectiveness, according to data on fraud review trade-offs in returns workflows.
That should change how you design review rules. If the system blocks too aggressively, good customers get treated like abusers. They face delays, denials, or confusing exceptions. Some won't reorder.
A better approach is tiered review:
Low-risk cases: Let the system approve automatically.
Mid-risk cases: Request additional validation or route for lightweight review.
High-risk cases: Send to a trained human queue with clear decision criteria.
This keeps speed where speed helps, and judgment where judgment matters.
Automation should remove repetitive work. It shouldn't eliminate discretion in edge cases that affect customer trust.
Automating broken policies
Some brands digitize a policy that already frustrates customers. That doesn't improve the experience. It makes the frustration faster.
If your return windows, item conditions, or category exceptions are confusing, a portal won't fix that. It will expose it more clearly. Before rollout, pressure-test the policy language with support and warehouse leads. If they interpret rules differently, customers will too.
A practical test is simple. Ask three teams how a specific return should be handled. If you get three answers, your automation project isn't ready for full scale.
Ignoring geographic and operational variation
Another common failure appears when businesses expand across regions, carriers, or warehouse networks. A rule that works in one market may break in another because of shipping constraints, local compliance needs, or different warehouse capabilities.
That's why modular logic matters. Keep shared policy principles consistent, but let routing, carrier options, and exception handling adapt at the facility or market level. Otherwise you end up enforcing uniform workflows on non-uniform operations.
Treating adoption as a software issue
Internal resistance usually isn't about the tool itself. It's about control, visibility, and accountability.
Support worries the system will trap them with angry customers. Warehouse teams worry the software won't reflect item condition on the floor. Finance worries automation will create reconciliation noise. Those concerns are legitimate. The solution isn't a kickoff deck. It's role-specific design.
Use these adoption habits:
Show event visibility clearly: Each team needs to see what changed and why.
Write exception rules down: Don't rely on tribal knowledge after go-live.
Review edge cases weekly at first: Tight feedback loops prevent distrust from hardening.
Measure bypass behavior: If people keep handling cases outside the system, find out why.
The best returns programs don't chase full automation in the abstract. They build reliable automation for the common path and well-governed human review for everything else.
Measuring ROI and Real-World Impact
The ROI case for returns management automation is broader than labor savings. You should measure hard savings, but don't stop there. The full payoff shows up when the business retains more revenue, resolves customer issues faster, and gets inventory back into circulation without delay.
Start with a simple framework.
ROI area | What to measure |
|---|---|
Operational savings | Lower handling effort, fewer manual touches, less avoidable shipping |
Support efficiency | Fewer status questions and exception escalations |
Revenue recovery | More exchanges and fewer unnecessary refunds |
Inventory productivity | Faster reintegration of resaleable units |
Customer value | Repeat purchase behavior and reduced post-purchase friction |
The most useful ROI models compare current-state costs against post-implementation performance by category or workflow. If you need a broader template for framing this kind of analysis, this guide to calculating total return on investment is a helpful starting point.
The practical impact tends to show up in a recognizable pattern. Support spends less time answering the same return questions. Warehouse teams receive cleaner instructions. Finance chases fewer exceptions. Customers choose exchanges more often when they're offered at the right moment. Merchandising gets better data on which SKUs create preventable returns.
That's why returns management automation has become a competitive requirement. It doesn't just reduce cost. It protects margin, improves loyalty, and gives operators a system they can scale without rebuilding the process every time volume increases.
If you like businesses that replace manual guesswork with automated decisioning, Yield Seeker is worth a look. It applies that same principle to stablecoin yield by using an AI-powered agent to monitor DeFi opportunities and allocate USDC based on user preferences, with a low-friction interface and accessible funds.